 Datasets
Datasets
 Models
Models
Downloads: 1
Diff of
/README.md
[000000]
..
[eac570]
Switch to unified view
| a | b/README.md | ||
|---|---|---|---|
| 1 | # 3D Neural Network for Lung Cancer Risk Prediction on CT Volumes |
||
| 2 | |||
| 3 | <!--- |
||
| 4 | [](https://doi.org/10.5281/zenodo.3950478) |
||
| 5 | --> |
||
| 6 | |||
| 7 | ### Overview |
||
| 8 | |||
| 9 | This repository contains my implementation of the "full-volume" model from the paper: |
||
| 10 | |||
| 11 | [End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography.](https://doi.org/10.1038/s41591-019-0447-x)<br/> Ardila, D., Kiraly, A.P., Bharadwaj, S. et al. Nat Med 25, 954–961 (2019). |
||
| 12 | |||
| 13 | 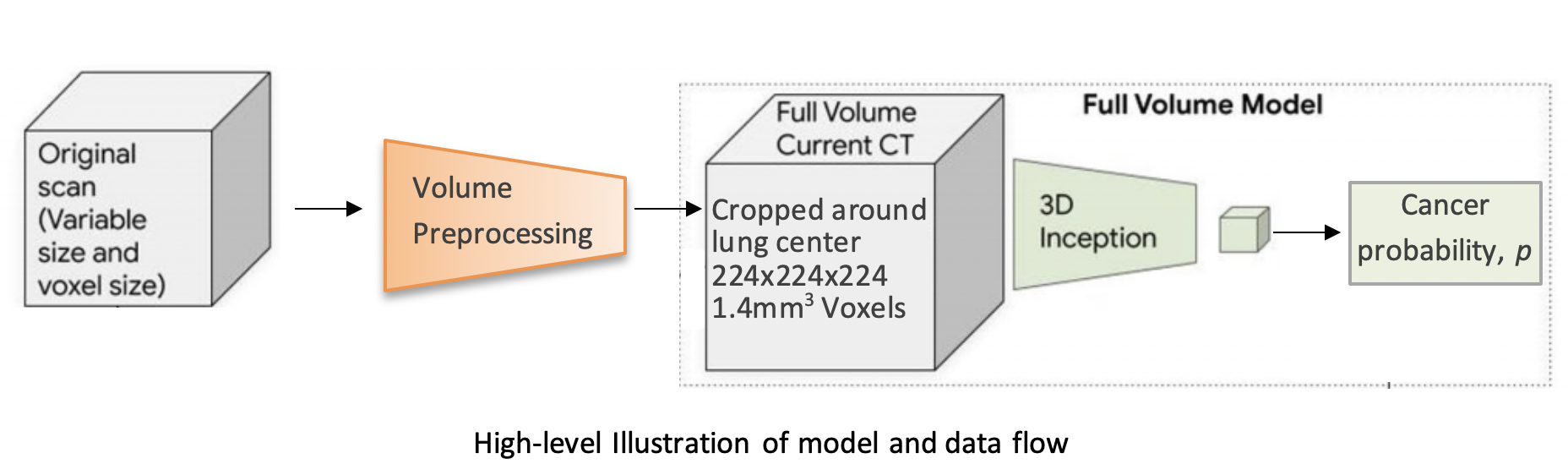 |
||
| 14 | |||
| 15 | The model uses a three-dimensional (3D) CNN to perform end-to-end analysis of whole-CT volumes, using LDCT |
||
| 16 | volumes with pathology-confirmed cancer as training data. |
||
| 17 | The CNN architecture is an Inflated 3D ConvNet (I3D) ([Carreira and |
||
| 18 | Zisserman](http://openaccess.thecvf.com/content_cvpr_2017/html/Carreira_Quo_Vadis_Action_CVPR_2017_paper.html)). |
||
| 19 | |||
| 20 | ### High-level Presentation |
||
| 21 | |||
| 22 | [](http://www.youtube.com/watch?v=KPBEpc_yDRk) |
||
| 23 | |||
| 24 | ### Detailed Report |
||
| 25 | For more detailed information, see this [report](https://arxiv.org/abs/2007.12898) on arXiv. |
||
| 26 | |||
| 27 | ### Data |
||
| 28 | |||
| 29 | We use the NLST dataset which contains chest LDCT volumes with pathology-confirmed cancer evaluations. For description and access to the dataset refer to the [NCI website](https://biometry.nci.nih.gov/cdas/learn/nlst/images/). |
||
| 30 | |||
| 31 | 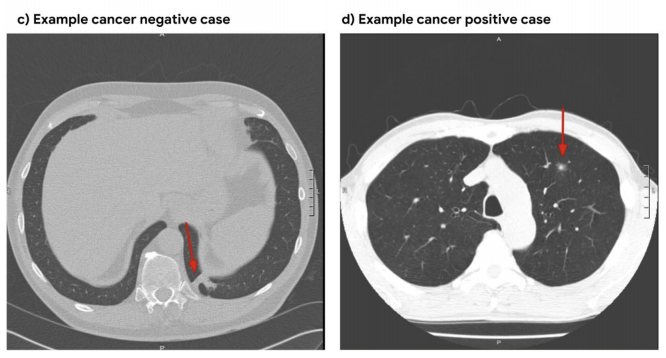 |
||
| 32 | |||
| 33 | ### Setup |
||
| 34 | |||
| 35 | ```bash |
||
| 36 | pip install lungs |
||
| 37 | ``` |
||
| 38 | |||
| 39 | ### Running the code |
||
| 40 | |||
| 41 | #### Inference |
||
| 42 | |||
| 43 | ```python |
||
| 44 | import lungs |
||
| 45 | lungs.predict('path/to/data') |
||
| 46 | ``` |
||
| 47 | |||
| 48 | From command line (with preprocessed data): |
||
| 49 | |||
| 50 | ```bash |
||
| 51 | python main.py --preprocessed --input path/to/preprocessed/data |
||
| 52 | ``` |
||
| 53 | |||
| 54 | #### Training |
||
| 55 | |||
| 56 | The inputs to the training procedure are training and validation `.list` files containing coupled data - a volume path and its label in each row. |
||
| 57 | These `.list` files need to be generated beforehand using `preprocess.py`, as described in the next section. |
||
| 58 | |||
| 59 | ```python |
||
| 60 | import lungs |
||
| 61 | # train with default hyperparameters |
||
| 62 | lungs.train(train='path/to/train.list', val='path/to/val.list') |
||
| 63 | ``` |
||
| 64 | |||
| 65 | The `main.py` module contains training (fine-tuning) and inference procedures. |
||
| 66 | The inputs are preprocessed CT volumes, as produced by `preprocess.py`. |
||
| 67 | For usage example, refer to the arguments' description and default values in the bottom of `main.py`. |
||
| 68 | |||
| 69 | ### Data Preprocessing |
||
| 70 | |||
| 71 | #### Preprocess volumes |
||
| 72 | |||
| 73 | Each CT volume in NLST is a **directory** of DICOM files (each `.dcm` file is one slice of the CT). |
||
| 74 | The `preprocess.py` module accepts a directory `path/to/data` containing **multiple** such directories (volumes). |
||
| 75 | It performs several preprocessing steps, and writes each preprocessed volume as an `.npz` file in `path/to/data_preprocssed`. |
||
| 76 | These steps are based on [this](https://www.kaggle.com/gzuidhof/full-preprocessing-tutorial/notebook) tutorial, and include: |
||
| 77 | |||
| 78 | - Resampling to a 1.5mm voxel size (slow) |
||
| 79 | - Coarse lung segmentation – used to compute lung center for alignment and reduction of problem space |
||
| 80 | |||
| 81 | To save storage space, the following preprocessing steps are performed online (during training/inference): |
||
| 82 | |||
| 83 | - Windowing – clip pixel values to focus on lung volume |
||
| 84 | - RGB normalization |
||
| 85 | |||
| 86 | Example usage: |
||
| 87 | |||
| 88 | ```python |
||
| 89 | from lungs import preprocess |
||
| 90 | # Step 1: Preprocess all volumes, will save them to '/path/to/dataset_preprocessed' |
||
| 91 | preprocess.preprocess_all('/path/to/dataset') |
||
| 92 | ``` |
||
| 93 | |||
| 94 | #### Create train/val `.list` files |
||
| 95 | |||
| 96 | Once the preprocessed data is ready, the next step is to split it randomly into train/val sets, |
||
| 97 | and save each set as a `.list` file of paths/labels, required for the training procedure. |
||
| 98 | |||
| 99 | Example usage: |
||
| 100 | |||
| 101 | ```python |
||
| 102 | from lungs import preprocess |
||
| 103 | # Step 2: Split preprocessed data into train/val coupled `.list` files |
||
| 104 | preprocess.split(positives='/path/to/dataset_preprocessed/positives', |
||
| 105 | negatives='/path/to/dataset_preprocessed/negatives', |
||
| 106 | lists_dir='/path/to/write/lists', |
||
| 107 | split_ratio=0.7) |
||
| 108 | ``` |
||
| 109 | |||
| 110 | ### Provided checkpoint |
||
| 111 | |||
| 112 | By default, if the `ckpt` argument is not given, the model is initialized using our best fine-tuned checkpoint. |
||
| 113 | Due to limited storage and compute time, our checkpoint was trained on a small subset of NLST containing 1,045 volumes (34% positive). |
||
| 114 | |||
| 115 | **Note that in order to obtain a general purpose prediction model, one would have to train on the full NLST dataset. Steps include:** |
||
| 116 | |||
| 117 | - Gaining access to the [NLST dataset](https://biometry.nci.nih.gov/cdas/learn/nlst/images/) |
||
| 118 | - Downloading<sup>1</sup> ~6TB of positive and negative volumes (requires storage and a few days for downloading) |
||
| 119 | - Preprocessing (see Data Preprocessing section above) |
||
| 120 | - Training (requires a capable GPU) |
||
| 121 | |||
| 122 | Even though we used a small subset of NLST, we still achieved a state-of-the-art AUC score of 0.892 on a validation set of 448 volumes. |
||
| 123 | This is comparable to the original paper's AUC for the full-volume model (see the paper's supplementary material), trained on 47,974 volumes (1.34% positive). |
||
| 124 | |||
| 125 | To train this model we first initialized by bootstrapping the filters from the [ImageNet pre-trained 2D Inception-v1 model]((http://download.tensorflow.org/models/inception_v1_2016_08_28.tar.gz)) into 3D, as described in the I3D paper. |
||
| 126 | It was then fine-tuned on the preprocessed CT volumes to predict cancer within 1 year (binary classification). Each of these volumes was a large region cropped around the center of the bounding box, as determined by lung segmentation in the preprocessing step. |
||
| 127 | |||
| 128 | For the training setup, we set the dropout keep_prob to 0.7, and trained in mini-batches of size of 2 (due to limited GPU memory). We used `tf.train.AdamOptimizer` with a small learning rate of 5e-5, (due to the small batch size) and stopped the training before overfitting started around epoch 37. |
||
| 129 | The focal loss function from the paper is provided in the code, but we did not experience improved results using it, compared to cross-entropy loss which was used instead. The likely reason is that our dataset was more balanced than the original paper's. |
||
| 130 | |||
| 131 | The follwoing plots show loss, AUC, and accuracy progression during training, along with ROC curves for selected epochs: |
||
| 132 | |||
| 133 | <img src="https://raw.githubusercontent.com/danielkorat/Lung-Cancer-Risk-Prediction/master/figures/loss.png" width="786" height="420"> |
||
| 134 | <img src="https://raw.githubusercontent.com/danielkorat/Lung-Cancer-Risk-Prediction/master/figures/auc_and_accuracy.png" width="786" height="420"> |
||
| 135 | |||
| 136 | <img src="https://raw.githubusercontent.com/danielkorat/Lung-Cancer-Risk-Prediction/master/figures/epoch_10.png" width="270" height="270"><img src="https://raw.githubusercontent.com/danielkorat/Lung-Cancer-Risk-Prediction/master/figures/epoch_20.png" width="270" height="270"><img src="https://raw.githubusercontent.com/danielkorat/Lung-Cancer-Risk-Prediction/master/figures/epoch_32.png" width="270" height="270"> |
||
| 137 | |||
| 138 | ### Citation |
||
| 139 | |||
| 140 | ```bibtex |
||
| 141 | @software{korat-lung-cancer-pred, |
||
| 142 | author = {Daniel Korat}, |
||
| 143 | title = {{3D Neural Network for Lung Cancer Risk Prediction on CT Volumes}}, |
||
| 144 | month = jul, |
||
| 145 | year = 2020, |
||
| 146 | publisher = {Zenodo}, |
||
| 147 | version = {v1.0}, |
||
| 148 | doi = {10.5281/zenodo.3950478}, |
||
| 149 | url = {https://doi.org/10.5281/zenodo.3950478} |
||
| 150 | } |
||
| 151 | ``` |
||
| 152 | |||
| 153 | ### Acknowledgments |
||
| 154 | |||
| 155 | The author thanks the National Cancer Institute for access to NCI's data collected by the National Screening Trial (NLST). |
||
| 156 | The statements contained herein are solely those of the author and do not represent or imply concurrence or endorsement by NCI. |
||
| 157 | |||
| 158 | <sup>1</sup> Downloading volumes is done by querying the TCIA website (instruction on NCI website). We used the following query filters: |
||
| 159 | |||
| 160 | - `LungCancerDiagnosis.conflc == "Confirmed.."` (positive) or `"Confirmed Not..."` (negative) |
||
| 161 | - `SCTImageInfo.numberimages >= 130` (minimum number of slices) |
||
| 162 | - `SCTImageInfo.reconthickness < 5.0` (maximum slice thickness) |
||
| 163 | - `ScreeningResults.study_yr = x` (study year of volume, a number between 0 and 7) |
||
| 164 | - `LungCancerDiagnosis.cancyr = x` or `x + 1` (for positives: study year of patient's cancer diagnosis is equal to `study_yr` or 1 year later) |
||
| 165 | |||
| 166 | ### All Links |
||
| 167 | |||
| 168 | [GitHub Pages](https://danielkorat.github.io/Lung-Cancer-Risk-Prediction) |
||
| 169 | [arXiv Report](https://arxiv.org/abs/2007.12898) |
||
| 170 | [Presentation Video](http://www.youtube.com/watch?v=KPBEpc_yDRk) |
||
| 171 | [Presentation PDF](https://drive.google.com/file/d/1Wya9drNmXwdwWiwzeoKxgHmQ3r19Xa6Q/view?usp=sharing) |
||
| 172 | DOI: [https://doi.org/10.5281/zenodo.3950478](https://doi.org/10.5281/zenodo.3950478) |